参考内容:
《深入理解计算机系统》(第三版)
字数据大小
前面已经提到过信息=位+上下文,但是基本上的计算机都没有将位作为最小的可寻址单位,而是将字节作为了最小的可寻址单位,内存就是一个非常大的字节数组,它的的每个字节都由一个唯一的数字来标识(这个数字是不需要存的),所有可能的地址集合就是虚拟地址空间。
我们常说的 32 位、64 位指的是一台计算机的字长,用于指明指针数据的的标称大小。有的面试官在面试的时候会问这样一个问题:在 C/C++ 中指针的大小是多少?如果你一下就回答出来时多少个字节了,那基本上不必再问了,因为一个指针的大小取决于计算机的字长,所以应该分 32 位机还是 64 位机的情况。
字长还会决定一个极为重要的系统参数——虚拟地址空间。比如现在有一个 32 位机,每一位可以取值 1 或 总共 32 位,能组合的出局就有 232 个,所以它能访问 232 个地址,其大小也就是 4G,因此你如果给 32 位机装上 8G 的内存条,是起不了多大作用的。
我们平时所说的 32 位程序和 64 位程序并不是指机器的字长,它们的区别在于程序时如何编译的,而不是其运行的机器类型,高版本都应该做到向后兼容,所以 32 位程序一般都能运行在 64 位机器上,而 64 位程序时不能运行在 32 位机上面的。下面两种伪指令就分别用于编译 32 位程序和 64 位程序。
gcc -m32 prog.c
gcc -m64 prog.c
C 语言在 32 位机和 64 位机上所表现的差别在于long数据类型,一般在 32 位机上是 4 个字节,而在 64 位机上是 8 个字节,而作为程序员要力图程序能在不同的机器上进行编译执行,要做到这一点就需要保证程序对不同数据类型的确切大小不敏感。
曾经某运营商的一个基站版本因为数据范围的不同而造成了巨大的损失,在编程环境中使用的是 32 位机,而基站所使用的处理器没有 32 位,最后表现的效果就是大概每隔 40 天,基站就自动复位了。定位到这个问题都花费了巨大的财力和人力资源。
寻址及字节顺序
上文已经提到,有很多的对象实际上不止占用一个字节,而是占用了多个字节,此时就涉及到如何排列这些字节了,以及如何存储这些字节。以11001100 11001100为例,它占用了两个字节,我们可以选择将这两个字节放在连续的内存中,也可以将两个字节分开放在不连续的内存中;另外我们可以将左边的字节当做起始位置,也可以将右边的字节当做起始位置(更专业的称为大端法和小端法)。
对于字节的排列,到底是用大端法还是小端法,没有技术上的争论,只有社会政治论题的争论,而且机器它对程序员是完全不可见的。几乎所有的机器都将多字节对象存储为连续的字节序列,所使用字节中最小的地址作为对象的地址。
那么什么时候需要注意字节的顺序规则呢,那就是编写网络应用程序的时候,试想你传输的数据是用大端法表示的,而用户的计算机采用的是小端法,那还会有用户使用你的产品吗。所以编写网络程序时需要遵循已经建立的关于字节顺序的规则。
整数表示
程序员对二进制不会不知道,比如 11111111表示的是 255(不考虑补码),很容易就能转换为我们所熟悉的 10 进制数据。这种方式我们默认它是无符号数,如果要加入有符号数就开始变得有趣了。
几乎所有的计算机都是采用有补码来表示有符号整数的,它与无符号整数的区别在于最高位被解释为负权,举个例子:将1111看做补码的话,它的值就为:-23 + 22 + 21 + 20 = -1。
在程序中不可避免的会使用强制类型转换,C 语言中强制类型转换并没有改变数据的位值,只是改变了解释这些位的方式。比如将无符号数(unsigned) 53191 转换为有符号数的结果为 -12345,它们的位值是完全没有相同的。
最容易入坑的地方是,对两个不同类型的数据进行运算时,C 语言将会隐式的将有符号数转换为无符号数,所以就有下面这样一个神奇的结果。
// u 代表无符号数
-1 < 0u
// 结果为 0
// 因为 -1 的补码表示为:11...11
// 转换为无符号数后就是范围内最大的数
如果需要扩展一个数的位表示,那么放心的扩展就好了,小的数据类型都能安全的向大的数据类型转换,补码表示的数会在前面补上符号位,原码表示的直接在前面补上 0 即可,而需要注意的是从大往小转,这会不可避免的截断位,造成信息的丢失,所以千万不要这么干。
加法、乘法运算
在编程入门的时候可能都知道两个正数相加的结果可能为负数,还有一个更奇怪的现象就是:x < y和 x - y < 0两个表达式可能会得出不一样的结果,这些神奇的结果都和计算机整数的底层表示和运算有着密切的关系。
C 语言中有无符号数与有符号数之分,而在 Java 中只有有符号数,下面的内容还是基于 C 语言进行说明,毕竟更 C 比 Java 更接近底层嘛。
无符号加法
假设我们使用 w 位来表示无符号数,那么两个加数取值范围即为:0 ≤ x, y <2w,理论上它们的和的范围为:0 ≤ sum < 2w+1,因为只有 w 位表示无符号数(要把和表示出来就需要 w+1 位),所以超过 zw的部分就会造成溢出,如下图所示。
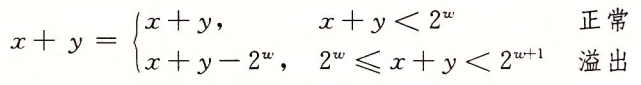
对于无符号数的溢出,计算机采用的处理方式是丢掉最高位,直观的结果就是,当发生溢出了,就将采用取模运算(或者说是减去 2w),举个例子。
只用 4 为来表示无符号数,即 w = 4,现在有 x [1001] 和 y [1100] 相加,其结果应为:[10101] ,但是没有 5 位用来表示,所以丢掉最高位的1,剩下的值为 5 [0101],也就是 21 mod 16 = 5。
那么如何检测是否发生溢出呢?设求和结果为 s,对于加法有 x + y ≥ x 恒成立,即只要没有发生溢出,肯定有 s ≥ x。另一方面,如果确实发生溢出了,就有 s = x + y - 2w,又有 y - 2w < 0,因此 s = x + y - 2w < x。
补码加法
和前面一样,对于两个给定范围的加数 - 2w-1 ≤ x, y ≤ 2w-1 - 1,它们的和的范围就在 - 2w ≤ sum ≤ 2w - 2。要想把整个和的范围表示出来,依旧需要 w+1 位才行,而现在只有 w 位,因此还是需要采用将溢出部分截断。
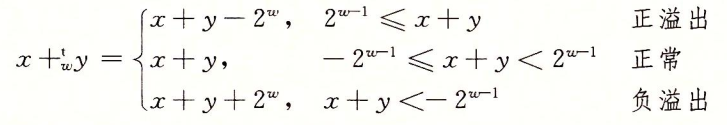
可以发现,当发生正溢出时,截断的结果是从和数中减去了 2w;而当发生负溢出时,截断结果是把和数加上 2w。
那么对于补码加法如何检测溢出结果呢?通过分析可以发现,当且仅当 x > 0, y > 0,但和 s ≤ 0 时为正溢出;当且仅当 x < 0, y < 0,但 s ≥ 0 时发生负溢出。
无符号乘法
有了前面的基础,乘法就变得简单一些了,对于溢出情况,计算机仍然采用的是求模,比如 0 ≤ x, y ≤ 2w - 1,它们乘积的范围为 0 到 22w - 2w+1 + 1 之间,这可能需要 2w 位来表示,溢出部分直接截掉,如下所示。
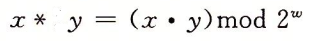
补码乘法
对于补码,两个乘数的范围为:- 2w-1 ≤ x, y ≤ 2w-1 + 1,那么其乘积表示范围就为 - 22w-2 + 2w-1 到 22w-2 之间,补码乘法和无符号乘法基本是一样的,只是在无符号基础上多加了一步转换,即将无符号数转换为补码。
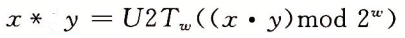
乘以常数
我们知道,计算机做加减法、位级运算的速度最快(1 个指令周期),而做乘除法很慢(10 个甚至更多指令周期),平时编写的程序中常常会乘以一个常数,为了使程序运行的更快,编译器可能会帮我们做一些处理。
首先我们考虑常数是 2 的幂。x * 21 可以表示为 x << 1,x * 22 可以表示为 x << 2,依次类推即可。
对于不是 2 的幂的常数,比如 x * 14 可以表示为:(x<<3) + (x<<2) + (x<<1),因为 14 = 23 + 22 + 21;聪明的你可能发现 14 还有另一种表示方法,即 14 = 24 - 21,这种表示比前一种表示方法又少了运算量,所以 x * 14 还可以表示为:(x<<4) - (x<<1)。
实际上,这里有一个通用的解决方案,对于任何一个常数 K,其二进制可以表示为一组 0 和 1 交替的序列:[(0...0)(1...1)(0...0)(1...1)],14可以表示为:[(0...0)(111)(0)],考虑一组从位位置 n 到位位置 m 的连续的 1 (n ≥ m),(对于 14 有 n = 3,m = 1)可以有两种形式来计算位对乘积的影响。
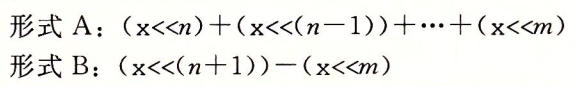
这个优化不是一定的,大多数编译器只在需要少量移位、加减法就足够的时候才使用这种优化。