参考内容:
《编译原理》
实现简单的正则表达式引擎
正则表达式回溯原理
浅谈正则表达式原理
最近在一个业务问题中遇到了一个正则表达式性能问题,于是查了点资料去回顾了下正则表达式的原理,简单整理了一下就发到这里吧;另外也是想试试 Apple Pencil 的手感如何,画的太丑不要嫌弃哈。
有穷自动机
正则表达式的规则不是很多,这些规则也很容易就能理解,但是正则表达式并不能用来直接识别字符串,我们还需要引入一种适合转换为计算机程序的模型,我们引入的就是有穷自动机。
在编译原理中通过构造有穷自动机把正则表达式编译成识别器,识别器以字符串x作为输入,当x是语言的句子时回答是,否则回答不是,这正是我们使用正则表达式时需要达到的效果。
有穷自动机分为确定性有穷自动机(DFA)和非确定性有穷自动机(NFA),它们都能且仅能识别正则表达式所表示的语言。它们有着各自的优缺点,DFA 导出的识别器时间复杂度是多项式的,它比 NFA 导出的识别器要快的多,但是 DFA 导出的识别器要比与之对应的 NFA 导出的识别器大的多。
大部分正则表达式引擎都是使用 NFA 实现的,也有少部分使用 DFA 实现。从我们写正则表达式的角度来讲,DFA 实现的引擎要比 NFA 实现的引擎快的多,但是 DFA 支持的功能没有 NFA 那么强大,比如没有捕获组一类的特性等等。
我们可以用带标记的有向图来表示有穷自动机,称之为转换图,其节点是状态,有标记的边表示转换函数。同一个字符可以标记始于同一个状态的两个或多个转换,边可以由输入字符符号标记,其中 NFA 的边还可以用ε标记。
之所以一个叫有确定和非确定之分,是因为对于同一个状态与同一个输入符号,NFA 可以到达不同的状态。下面看两张图就能明白上面那一长串的文字了。
图中两个圈圈的状态表示接受状态,也就是说到达这个状态就表示匹配成功。细心的你应该发现了两张图所表示的正则表达式是一样的,这就是有穷自动机神奇的地方,每一个 NFA 我们都能通过算法将其转换为 DFA,所以我们先根据正则表达式构建 NFA,然后再转换成相应的 DFA,最后再进行识别。
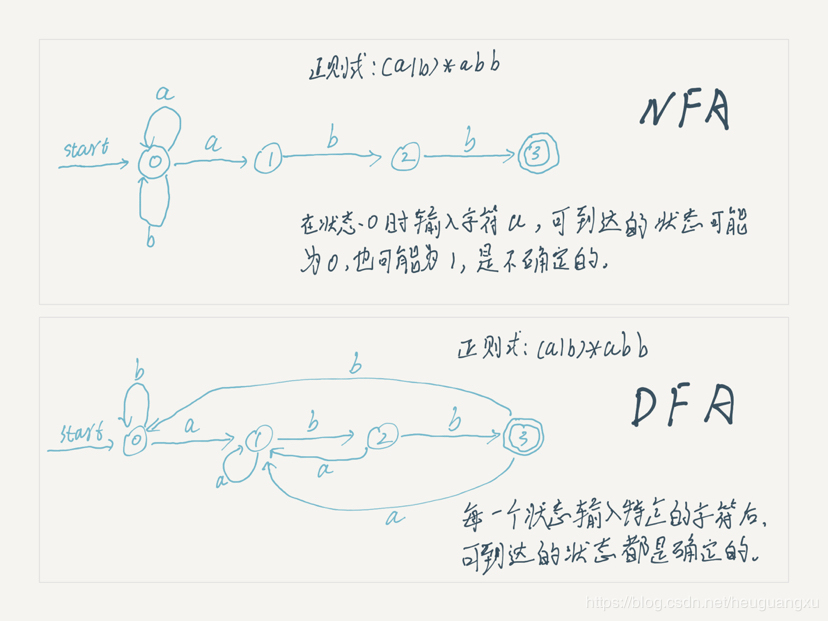
上图的画法在正则表达式很简单的时候还可以,如果遇到很复杂的正则表达式画起来还是挺费力的,如果想对自动机有更加深入的认识可以自行查阅相关资料。下面的图片是使用正则可视化工具生成的,对应的正则表达式是^-?\d+(,\d{3})*(\.\d{1,2})?$,它所匹配的字符串是数字/货币金额(支持负数、千分位分隔符)。

回溯
NFA 引擎在遇到多个合法的状态时,它会选择其中一个并记住它,当匹配失败时引擎就会回溯到之前记录的位置继续尝试匹配。这种回溯机制正是造成正则表达式性能问题的主要原因。下面我们通过具体的例子来看看什么是回溯。
/ab{1,3}c/
| 正则 | 文本 |
|---|---|
| ab{1,3}c | abbbc |
ab{1,3}c |
abbbc |
ab{1,3}c |
abbbc |
ab{1,3}c |
abbbc |
ab{1,3}c |
abbbc |
ab{1,3}c |
abbbc |
上表中展示的是使用ab{1,3}c匹配abbbc的过程,如果把匹配字符串换成abbc,在第五步就会出现匹配失败的情况,第六步会回到上一次匹配正确的位置,进而继续匹配。这里的第六步就是「回溯」
| 正则 | 文本 | 备注 |
|---|---|---|
| ab{1,3}c | abbc | |
ab{1,3}c |
abbc |
|
ab{1,3}c |
abbc |
|
ab{1,3}c |
abbc |
|
ab{1,3}c |
abb |
匹配失败 |
ab{1,3}c |
abbc |
回溯 |
ab{1,3}c |
abbc |
会出现上面这种情况的原因在于正则匹配采用了回溯法。回溯法采用试错的思想,它尝试分步的去解决一个问题。在分步解决问题的过程中,当它通过尝试发现现有的分步答案不能得到有效的正确的解答的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。它通常采用最简单的递归来实现,在反复重复上述的步骤后可能找到一个正确的答案,也可能尝试所有的步骤后发现该问题没有答案,回溯法在最坏的情况下会导致一次复杂度为指数时间的计算。
上面一段的内容来源于维基百科,精简一下就是深度优先搜索算法。贪婪量词、惰性量词、分支结构等等都是可能产生回溯的地方,在写正则表达式时要注意会引起回溯的地方,避免导致性能问题。
John Graham-Cumming 在他的博文 Details of the Cloudflare outage on July 2, 2019 中详细记录了因为一个正则表达式而导致线上事故的例子。该事故就是因为一个有性能问题的正则表达式,引起了灾难性的回溯,进而导致了 CPU 满载。
(?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
上面是引起事故的正则表达式,出问题的关键部分在.*(?:.*=.*)中,就是它引起的灾难性回溯导致 CPU 满载。那么我们应该怎么减少或避免回溯呢?无非是提高警惕性,好好写正则表达式;或者使用 DFA 引擎的正则表达式。
[0-9] 与 \d 的区别
此问题来源于Stackoverflow,题主遇到的问题是\d比[0-9]的效率要低很多,并且给出了如下的测试结果,可以看到\d比[0-9]慢了差不多一倍。
Regular expression \d took 00:00:00.2141226 result: 5077/10000
Regular expression [0-9] took 00:00:00.1357972 result: 5077/10000 63.42 % of first
Regular expression [0123456789] took 00:00:00.1388997 result: 5077/10000 64.87 % of first
出现这个性能问题的原因在于\d匹配的不仅仅是0123456789,\d匹配的是所有的 Unicode 的数字,你可以从 Unicode Characters in the 'Number, Decimal Digit' Category 中看到所有在 Unicode 中属于数字的字符。
此处多提一嘴,[ -~]可以匹配 ASCII 码中所有的可打印字符,你可以查看 ASCII 码中的可显示字符,就是从" "(32)至"~"(126)的字符。
工具/资源推荐
正则表达式确实很强大,但是它那晦涩的语法也容易让人头疼抓狂,不论是自己还是别人写的正则表达式都挺头大,好的是已经有人整理了常用正则大全,也大神写了个叫做 VerbalExpressions 的小工具,主流开发语言的版本它都提供了,可以让你用类似于自然语言的方式来写正则表达式,下面是它给出的一个 JS 版示例。
// Create an example of how to test for correctly formed URLs
const tester = VerEx()
.startOfLine()
.then('http')
.maybe('s')
.then('://')
.maybe('www.')
.anythingBut(' ')
.endOfLine();
// Create an example URL
const testMe = 'https://www.google.com';
// Use RegExp object's native test() function
if (tester.test(testMe)) {
alert('We have a correct URL'); // This output will fire
} else {
alert('The URL is incorrect');
}
console.log(tester); // Outputs the actual expression used: /^(http)(s)?(\:\/\/)(www\.)?([^\ ]*)$/
文章大部分内容都是介绍的偏原理方面的知识,如果仅仅是想要学习如何使用正则表达式,可以看正则表达式语法或者 Learn-regex,更为详细的内容推荐看由老姚写的JavaScript 正则表达式迷你书