我们在编程序的时候,都会把某一个特定功能封装在一个函数里面,对外暴露一个接口,而隐藏了函数行为的具体实现,一个大型的复杂系统里面包含了很多这样的小函数,我们称之为过程。
过程是相对独立的小模块,系统的运行需要这些过程的紧密合作,这种合作就是函数调用。
在一个函数执行时调用别的函数,比如 P 调用 Q,需要执行一些特定的动作。传递控制,在调用 Q 之前,控制权在 P 的手里,既然要调用 Q,那么就需要把控制权交给 Q;传递数据,就是函数传参;分配与释放内存,在开始时,Q 可能需要位局部变量分配空间,结束时又必须释放这些存储空间。
大多数语言都使用栈提供的先进后出机制来管理内存,x86-64 可以通过通用寄存器传递最多 6 个整数值(整数或地址),如果超过 6 个,那就需要在栈中分配内存,并且通过栈传递参数时,所有数据的大小都要向 8 的倍数对齐。将控制权从 P 转交给 Q,只需要将 PC(程序计数器)的值置为 Q 代码的起始位置,并记录好 P 执行的位置,方便 Q 执行完了,继续执行 P 剩余的代码。
在函数的传参、执行中,多多少少都需要空间来保存变量,局部数据能保存在寄存器中就会保存在寄存器中,如果寄存器不够,将会保存在内存中。除了寄存器不够用的情况,还有数组、结构体和地址等局部变量都必须保存在内存中。分配内存很简单,只需要减小栈指针的值就行了,同样释放也只需要增加栈指针。
在函数执行过程中,处理栈指针%rsp,其它寄存器都被分类为被调用者保存寄存器,即当过程 P 调用过程 Q 时,Q 必须保存这些寄存器的值,保证它们的值在 Q 返回到 P 时与 Q 被调用时是一样的。
所以递归也就不难理解了,初学算法总觉得递归有点奇妙,怎么自己调用自己,而实际上对于计算机来说,它和调用其它函数没什么区别,在计算机眼里,没有自身与其它函数的区别,所有被调用者都是其它人。
数组是编程中不可或缺的一种结构,“数组是分配在连续的内存中”这句话已经烂熟于心了,历史上,C 语言只支持大小在编译时就能确定的多维数组,这个多多少少有一些不便利,所以在ISO C99标准中就引入了新的功能,允许数组的维度是表达式。
int A[expr1][expr2]
因为数组是连续的内存,所以很容易就能访问到指定位置的元素,它通过首地址加上偏移量即可计算出对应元素的地址,这个偏移量一定意义上就是由索引给出。
比如现在有一个数组A,那么A[i]就等同于表达式* (A + i),这是一个指针运算。C 语言的一大特性就是指针,既是优点也是难点,单操作符&和*可以产生指针和简介引用指针,也就是,对于一个表示某个对象的表达式expr,&expr给出该对象地址的一个指针,而对于一个表示地址的表达式Aexpr,*Aexpr给出该地址的值。
即使我们创建嵌套(多维)数组,上面的一般原则也是成立的,比如下面的例子。
int A[5][3];
// 上面声明等价于下面
typedef int row3_t[3];
row3_t A[5];
这个数组在内存的中就是下面那个样子的。

还有一个重要的概念叫做数据对齐,即很多计算机系统要求某种类型的对象的地址必须是某个值 K(一般是2、4 或 8)的倍数,这种限制简化了处理器和内存接口之间的设计,甚至有的系统没有进行数据对齐,程序就无法正常运行。
比如现在有一个如下的结构体。
struct S1 {
int i;
char c;
int j;
}
如果编译器用最小的 9 字节分配,那么将是下面的这个样子。
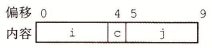
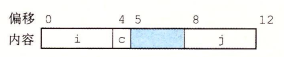
但是上面这种结构无法满足 i 和 j 的 4 字节对齐要求,所以编译器会在 c 和 j 之间插入 3 个字节的间隙。
在极客时间专栏中有这样一段代码。
int main(int argc, char *argv[]){
int i = 0;
int arr[3] = {0};
for(; i <= 3; i++){
arr[i] = 0;
printf("Hello world!\n");
}
return 0;
}
这段代码神奇的是在某种情况下会一直循环的输出Hello world,并不会结束,在计算机系统漫游(补充)中也提到过。
造成上面这种结果是因为函数体内的局部变量存在栈中,并且是连续压栈,而 Linux 中栈又是从高向低增长。数组arr中是 3 个元素,加上 i 是 4 个元素,刚好满足 8 字节对齐(编译器 64 位系统下默认会 8 字节对齐),变量i在数组arr之前,即i的地址与arr相邻且比它大。
代码中很明显访问数组时越界了,当i为 3 时,实际上正好访问到变量i的地址,而循环体中又有一句arr[i] = 0;,即又把i的值设置为了 0,由此就导致了死循环。